
Optical character recognition converts any kind of image containing written text into machine-readable text data. OCR allows you to quickly and automatically digitize a document without the need for manual data entry. The output of OCR is further used for electronic document editing, and compact data storage and forms the basis for cognitive computing, machine translation and text-to-speech technologies.
Let’s find out how OCR works. The functioning of the traditional optical character recognition system consists of three stages: image pre-processing, character recognition, post-processing.The main challenge of text recognition is that each document template has its own set of entities, values, and location of entities in the document. For OCR software to work accurately, it must be able to identify different types of documents and run the correct predefined pipeline based on that.
Most often, OCR programs with feature detection use classifiers based on machine learning or neural networks to process characters. Classifiers are used to compare image features with stored examples in the system and select the closest match. The feature detection algorithm is good for unusual fonts or low-quality images where the font is distorted.Once a symbol is identified, it is converted into a code that can be used by computer systems for further processing.
The high variability and often low quality of receipts are the main challenges for accurate receipt recognition with OCR. In such a case, the rule-based approach cannot be effective and this is where optical character recognition with deep learning comes in. The deep learning approach to OCR allows the system to learn from the received data and improve.
Using OCR with machine learning, retailers can experience the rapid development of internal business processes and improve the customer experience by making the most of the existing data. For example, merchants can extract valuable insights from purchase order analytics to create more effective marketing campaigns, promotions, and manage pricing better.
Since documents of the same type may have a different format depending on the country or state, the system must be able to find and extract the necessary data from all variations. Using deep learning algorithms helps the OCR system understand the relative positional relationship among different text blocks and combine pairs of semantically connected blocks of text to find relevant data such as name, date of birth, etc.
Open-source OCR can be integrated as separate client application cloud services. Such solutions don’t require a direct payment for the service, but involve the cost of maintaining the infrastructure for the functioning of OCR . Having a microservice also requires an Internet connection for OCR to work. However, there are also standalone optical character recognition systems that can function without the Internet.
Deutschland Neuesten Nachrichten, Deutschland Schlagzeilen
Similar News:Sie können auch ähnliche Nachrichten wie diese lesen, die wir aus anderen Nachrichtenquellen gesammelt haben.
 #FoundersConnect: Godwin Tom, Serial Entrepreneur, Music Business Mogul & CEO of iMANAGE AFRICA | HackerNoon'FoundersConnect: Godwin Tom, Serial Entrepreneur, Music Business Mogul & CEO of iMANAGE AFRICA' youtubetranscripts peaceitimi
#FoundersConnect: Godwin Tom, Serial Entrepreneur, Music Business Mogul & CEO of iMANAGE AFRICA | HackerNoon'FoundersConnect: Godwin Tom, Serial Entrepreneur, Music Business Mogul & CEO of iMANAGE AFRICA' youtubetranscripts peaceitimi
Weiterlesen »
 Examining Apps That Help Your Business Grow | HackerNoon'Examining Apps That Help Your Business Grow' mobileapplicationdevelopment webapplications
Examining Apps That Help Your Business Grow | HackerNoon'Examining Apps That Help Your Business Grow' mobileapplicationdevelopment webapplications
Weiterlesen »
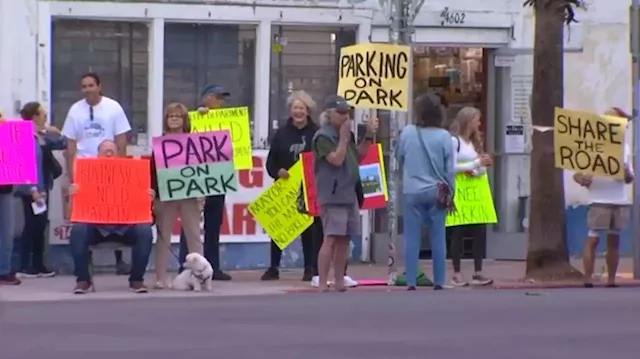 University Heights Business Owners Fume As City Begins Work on Protected Bike LanesThe protected bike lanes are part of the city’s 2022 resurfacing plan for the area and covers a one-mile stretch of Park Boulevard The city isn't for the tax paying citizens, it's for the weirdo fringe.
University Heights Business Owners Fume As City Begins Work on Protected Bike LanesThe protected bike lanes are part of the city’s 2022 resurfacing plan for the area and covers a one-mile stretch of Park Boulevard The city isn't for the tax paying citizens, it's for the weirdo fringe.
Weiterlesen »